고정 헤더 영역
상세 컨텐츠
본문
회사에서 연구팀으로 있으면서
신경망 업무를 진행중이지만
기본적인 지식이 부족하다고 느껴서
예전에 한글판 유튜브로 살짝 맛만봤던
cs231n 강의를 드디어 영어 원본?버전으로 공부를 시작했다.
이 블로그는 미래의 나를 위해
단순 기억용으로 적는 것이며
웬만하면 본인이 직접 강의를 보는 것을 추천한다!
이 글에 첨부하는 이미지와 모든 자료들은
스탠포드의 cs231n 자료를 참조하였음.
(문제될 시 댓글로 알려주시면 삭제하겠습니다!)
1강은 컴퓨터비전의 역사와 관련된 내용인데
눈으로만 훑고 정리는 스킵했다.
Image classification pipeline
Image Classification ?

Image Classification이란 입력 이미지(귀여운 고양이)를 받아
우리가 미리 정해놓은 카테고리 집합(강아지, 고양이, 트럭, 비행기 등 ) 중
어디에 속하는지 고르는 것이다.
사람에겐 쉽지만 컴퓨터에게는 매우 어려운 일이다.
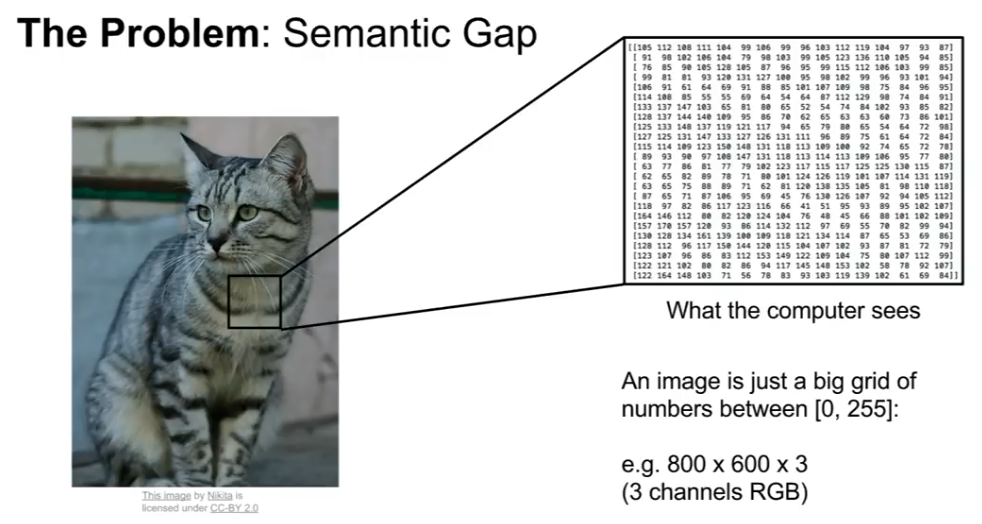
왜냐하면 컴퓨터에게 이미지는 큰 격자모양의 숫자 집합으로밖에 보이지 않기 때문이다.
이것을 의미론적인 차이(Sematic gap)이라고 한다.
이미지에 아주 미묘한 변화만 주더라도 픽셀값들은 모두 변하게 된다.
1. Viewpoint variation : 카메라를 옆으로 옮기거나, 고양이가 움직이거나 하는 경우
2. Illumination : 조명
3. Deformation : 변형(자세 등)
4. Occlusion : 가려짐
5. Background Clutter : 배경과 거의 비슷한 경우
6. Intraclass variation : 다양성(종, 크기, 색, 나이 등)
위와 같은 변화가 있을 때 모든 픽셀값들이 달라질 것이다.
우리는 이런 문제들에 강인한 모델을 만들어야 한다.
어떻게?
우리는 숫자를 정렬한다든가 하는 문제들에 대해서는
필요한 과정들을 나열하며 알고리즘을 써내려갈 수 있을 것이다.
하지만 고양이를 인식해야하는 상황에서
객체를 인식하기 위한 직관적이고 명시적인 알고리즘은
존재하지 않는다.
그래서 동물을 인식하기 위해 사람들은 많은 시도를 해봤는데
첫 번째로 규칙을 정하는 방법이다.
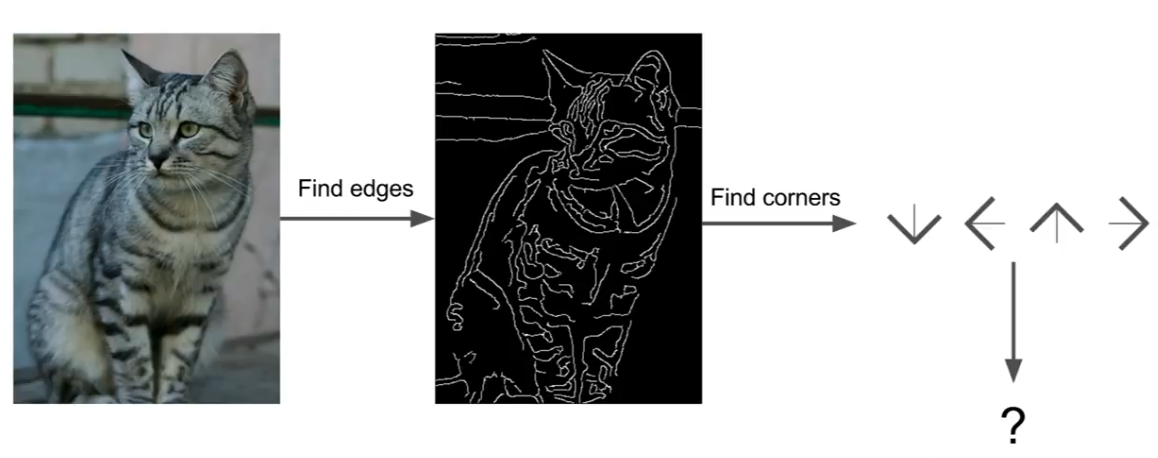
우리는 고양이가 두 개의 귀와 하나의 코가 있다는 것을 알고있다.
이미지에서 edge와 corner를 계산하여 각 카테고리로 분류한다.
만약 세 개의 선이 만나는 지점을 corner라고 했을 때 귀는 '여기에 corner하나, 저기에도 corner하나"가 있네~
이런 식으로 명시적인 규칙의 집합을 써내려가는 방법이다.
하지만 이런 방식의 알고리즘은 강인하지 못하다.
그리고 또 다른 객체를 인식해야한다면 트럭에 대해서도, 개에 대해서도 별도로 규칙을 만들어야한다.
그럼 처음부터 다시 시작해야한다!!
우리는 다양한 객체들에게 유연하게 적용 가능한 확장성 있는 알고리즘을 만들어야 한다.
이것이 가능한 하나의 insight 는 데이터 중심 접근방법(Data-Driven Approach)이다.

1. 충분한 양의 데이터를 수집한다.
2. Machine Learning Classifier를 학습
3. 새로운 이미지에 테스트
입력 이미지를 고양이로 인식하려면 이제는 함수가 두 개 필요하다.
입력이 이미지이고, 출력이 모델인 Train 함수와,
입력이 모델이고 출력이 이미지의 에측값인 Predict 함수이다.
Nearest Neighbor라는 아주 단순한 classifier가 있다.

train step 에서는 아무일도 하지 않고 단지 모든 학습 데이터를 기억한다.
그 다음 predict step에서는 새로운 이미지가 들어오면 기존 학습 데이터와 비교하여 가장 유사한 이미지로 예측한다.
유사한 이미지는 어떻게 찾을 것인가?
--> 어떤 비교함수를 사용할 것인가!
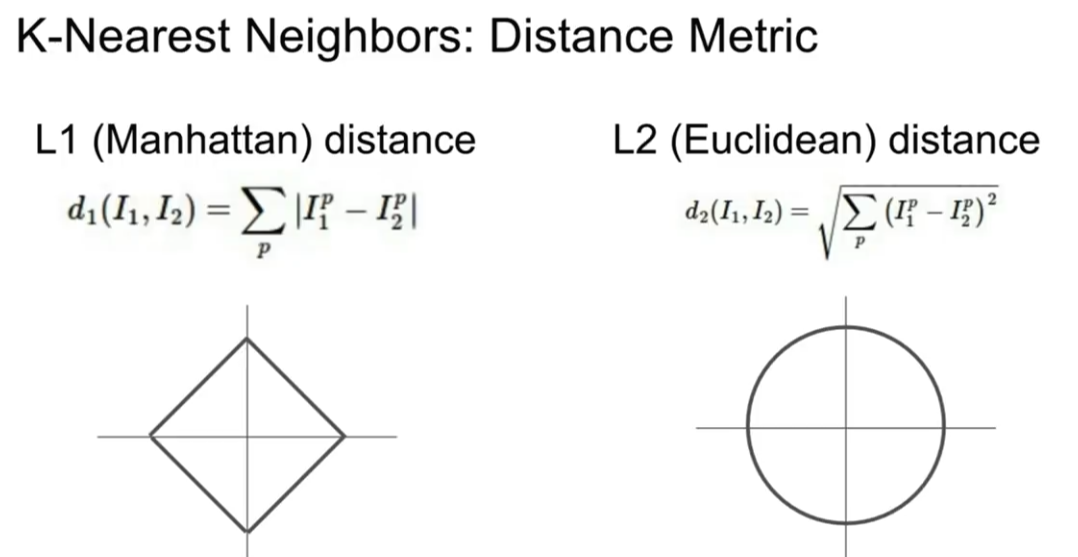
L1 distance 와 L2 distance가 있다.
왼쪽의 L1 distance는 Manhattan distance라고도 하며 픽셀간 차이 절대값의 합이다.
두 이미지의 같은 자리의 픽셀을 서로 빼고 절댓값을 취하여 모두 합하는 방식이다.
왼쪽의 사각형은 L1 distance관점에서는 원이다.
오른쪽의 L2 distance는 Euclidean distance로 제곱 합의 제곱근이다.
같은 자리의 픽셀을 서로 빼고 제곱하여 모두 더한 후 제곱근을 해준다.
마찬가지로 L2 distance관점에서 원이며, 우리가 예상했던 원이다.
L1은 어떤 좌표계냐에 따라 영향을 많이 받기 때문에 좌표를 회전하면 값이 변한다.
따라서 특징벡터의 각 요소들이 개별적인 의미를 가진 경우(키, 몸무게, 나이 등)에 조금 더 잘 어울린다.
L2는 좌표계와 아무 연관이 없기 때문에 특징벡터가 일반적인 벡터고 요소들간의 실질적인 의미를 모를 때 더 잘 어울린다.
k-nn은 단순한 알고리즘으로 거리를 어떻게 구할건지 거리 척도만 정해주면 어떤 종류의 데이터도 다룰 수 있다.
(k가 커질수록 경계가 부드러워짐 자세한 내용은 knn에 대해 찾아보시길)
k-nn에서와 같은 알고리즘을 사용하기 위해서는 선택해야하는 파라미터들이 있다.
k, 거리 척도 등이 그 예이며 이를 '하이퍼 파라미터'라고 한다.
이러한 하이퍼 파라미터는 학습 전에 반드시 선택해야 한다.
어떻게?
가장 간단한 방법은 데이터에 맞게 다양한 하이퍼 파라미터 값을 시도해보고 가장 좋은 값을 찾는 것이다.
시도하는 방법에는 여러가지가 있다.
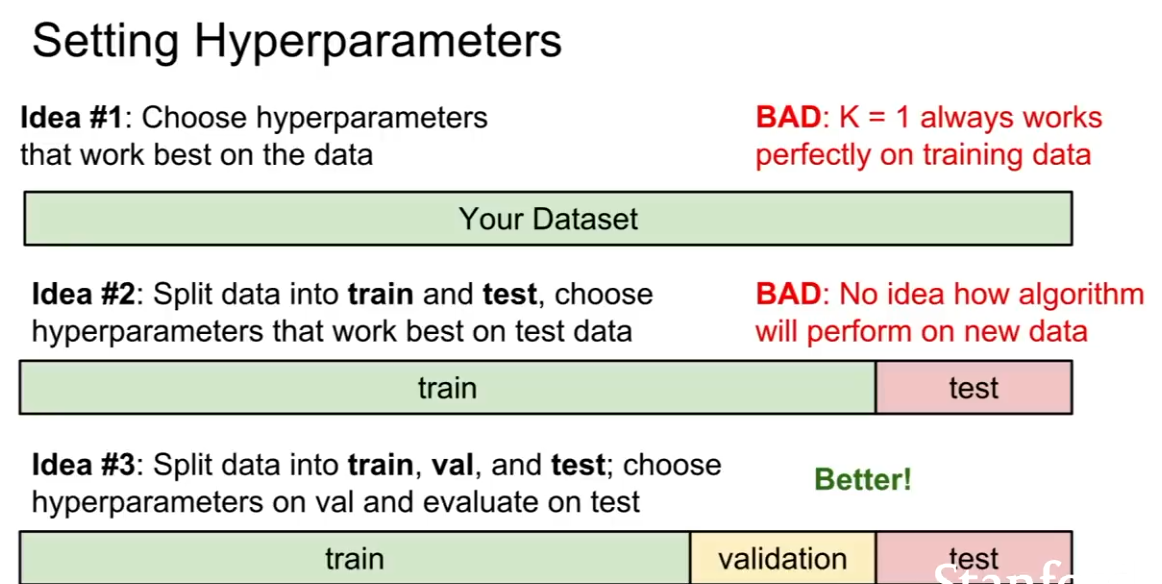
1. 학습 데이터의 정확도와 성능을 최대화 하는 하이퍼 파라미터를 선택
--> really terrible , 학습 데이터에 없던 데이터에 대해 예측을 잘 하는 것이 중요
2. 전체 데이터셋 중 학습 데이터를 쪼개서 일부를 테스트 데이터로 사용, 테스트 데이터의 성능이 가장 좋은 파라미터를 선택
--> also terrible, '테스트 셋에서만' 잘 동작하는 하이퍼파라미터를 고른 것일 수 있음, 테스트셋에서의 성능이 한 번도 보지 못한 데이터에서의 성능을 대표할 수는 없다.
3. 학습 데이터, 검증 데이터, 테스트 데이터로 나눈 후 검증 단계에서 하이퍼 파라미터를 선택한 뒤 테스트 데이터셋으로 실질적인 성능을 측정
--> 이 방법을 사용하는것이 제일 좋다!
하지만 실제로 입력이 이미지인 경우 k-NN 분류기는 잘 사용하지 않는다.
일단 너무 느리다. 우리는 학습이 느려도 테스트가 빠르길 원하는데 k-nn은 학습은 빠르지만 테스트가 느리다.
또 하나의 문제는 L1/L2 distance가 이미지 간의 거리를 측정하기에 적절하지 않다는 점이다.

위 네 장의 여자 이미지는 모두 같은 Distance를 갖는다.
얼굴이 가려지고, shift되고, 색감이 변했지만 같은 거리를 갖는다.
이는 L2 distance가 이미지들간의 유사도를 측정하기에는 적합하지 않다는 의미이다.

그리고 차원의 저주 문제도 있다.
차원이 커질수록 그 차원을 덮기 위한 점의 개수가 기하급수적으로 증가한다.
이는 차원이 커질수록 충분한 데이터셋이 필요한 것인데,
차원 증가에 따라 필요한 데이터의 양이 기하급수적으로 증가하기 때문에
충분한 데이터셋을 모으는 것이 현실적으로 불가능하다.
이렇게 되면 학습은 잘 되지 않을 것이고 테스트 이미지를 제대로 분류할 수 없을 것이다.
Linear Classification

Linear Classifier는 parametric model의 가장 단순한 형태이다.
input 이미지가 들어오면 어떤 함수 f를 거쳐서 각 class에 대한 score를 출력한다.
이 어떤 함수 f는 data x와 parameter W를 가진다.
딥러닝이란 이 f함수의 구조를 잘 설계하는 일이다.
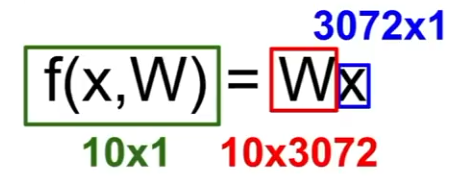
이는 가장 간단한 방식으로 W와 x를 곱하는 것이다.
차원을 보면 f의 출력은 10x1 (10개의 클래스로 가정) 이고,
x인 input 이미지는 32x32x3이었으니 이를 하나의 열벡터로 만들어서 3072x1이다.
3072 열벡터가 10개의 class score가 되어야하므로 행렬 W는 10x3072가 되어야 한다.
이 둘을 곱하면 10 class score를 의미하는 10x1 짜리 하나의 열벡터를 얻게 된다.
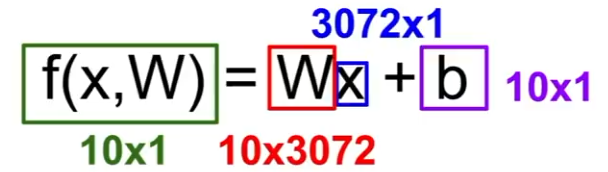
뒤에 bias term이 붙기도 하는데, 이는 데이터셋이 불균형한 상황에서 데이터와 무관하게 특정 클래스에 우선권을 부여하는 것이다.

3개의 클래스로 분류하는 모델이라고 했을 때 위와 같이 동작된다.
스코어는 입력 이미지의 픽셀 값들과 가중치 행렬을 내적한 값에 bias term을 더한것이다.
가중치 행렬과 픽셀 값인 열벡터를 곱하는 과정은 유사도를 측정하는 과정과 유사하다고 할 수 있고,
bias는 데이터 독립적으로 각 클래스에 scailing offset을 더해주는 것이다.

가중치 행렬 W의 한 행을 뽑아서 이미지로 시각화해보면 위와 같다.
보면 말같은 경우에는 머리가 두 개가 있다.
뭔가 이상하다!
이 방식은 각 하나의 class에 대해 하나의 템플릿만 학습할 수 있기 때문에 다양한 특징을 평균화하는 단점이 있다.
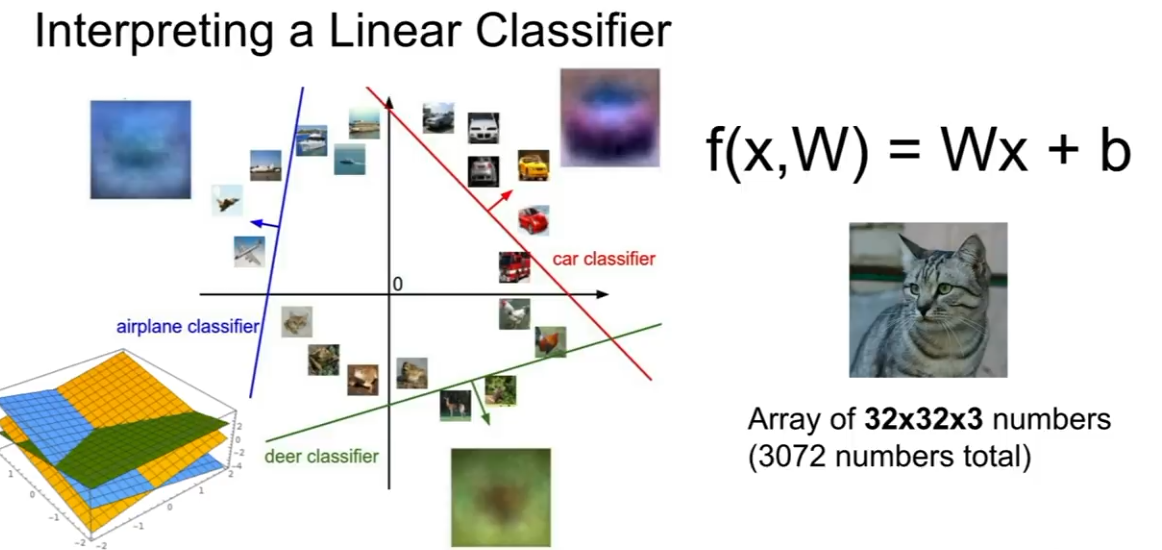
Linear classifier를 다른 관점으로 해석하면 이미지를 고차원 공간의 한 점으로 볼 수 있다.
Linear classifier는 각 클래스를 구분시켜 주는 선형 결정 경계를 그어주는 역할을 한다.
하지만 이런 Lear classification이 직면할 수 있는 문제가 있다.

이와 같이 parity problem , Multimodal problem과 같이
반정성 문제(홀/짝)나 한 클래스가 다양한 공간에 분포된 경우에
선 하나로 분류할 방법이 없기 때문에 Linear classifier로 풀기 힘들다.
이처럼 Linear classifier에는 문제점이 일부 있긴 하지만 아주 쉽게 이해하고 해석할 수 있는 알고리즘이다.
간단하게 정리하려고 했는데 적다보니 길어졌다...
근데 아마 3강부터는 진짜 간단하게만 적을 것 같다.
오늘이 금요일 저녁이라 열심히 써봤다 큼큼.
다음 강의도 미루지 않고 정리할 수 있길....
반응형
'Implement > __Theory' 카테고리의 다른 글
| [Deep Learning] 딥러닝 기반 객체 인식 기술 간단 정리(R-CNN, Fast R-CNN, Faster R-CNN, R-FCN, YOLO, SSD) (0) | 2021.08.12 |
|---|





댓글 영역