고정 헤더 영역
상세 컨텐츠
본문 제목
[Deep Learning] 딥러닝 기반 객체 인식 기술 간단 정리(R-CNN, Fast R-CNN, Faster R-CNN, R-FCN, YOLO, SSD)
본문
딥러닝 기반 객체 인식 기술 동향 간단 정리
(CNN모델은 다루지 않을 것)
논문 : https://www.koreascience.or.kr/article/JAKO201864236535536.pdf
객체 인식 기술
R-CNN : 딥러닝 회귀 방법으로 해결한 초기 연구, 느린 속도가 단점
Fast R-CNN : R-CNN의 느린 속도 보완, 객체의 후보영역을 찾는 데 딥러닝을 이용할 수 없다는 단점
Faster R-CNN : 검출 속도 향상, 딥러닝 만을 이용하여 객체 인식 구현, 영상의 지역적 정보에 의존적이라는 단점
R-FCN : 객체 인식 속도 크게 개선, but 실시간 처리 속도를 필요로 하는 분야에 적용하기엔 느림
YOLO : 객체 인식의 모든 과정을 하나의 네트워크로 구성 -> 속도 해결
SSD : 모바일에서도 동작 가능한 정도의 빠른 검출 속도
R-CNN
- 후보영역(Region Proposal)을 생성하고 이를 기반으로 CNN을 학습시켜 영상 내 객체의 위치를 찾아냄
- 인식 과정
1) 입력된 영상에서 선택적 탐색(Selective Search) 알고리즘을 이용하여 후보영역 생성
2) 후보영역들을 동일한 크기로 변환 후 CNN을 통해 특징(Feature) 추출
3) 추출된 특징을 이용하여 후보영역 내의 객체를 SVM을 이용하여 분류
- 1)에서 생성된 후보영역의 위치가 정확하지 않기 때문에 회귀 학습을 통해 박스 위치를 더 정확히 보정
- CNN, SVM, 회귀의 학습 단계가 모두 분리되어 있고, 수천 개의 후보 영역에서 각각 CNN을 학습해야 하므로 훈련 시간이 많이 소요
Fast R-CNN

- 하나의 입력 영상에 대해 하나의 CNN을 학습
- 학습된 CNN을 통해 생성된 Feature map을 pooling하여 특징 추출
- 분류기의 손실과 영역박스 회귀의 손실을 합하여 동시에 출력 -> 훈련 단계 단순화
- 분류기는 softmax (SVM보다 성능 우수)
- 후보영역을 생성하는 알고리즘이 CNN 외부에서 수행 -> 비효율적, 알고리즘 학습 불가
Faster R-CNN

- 후보 영역을 생성하는 데 선택적 탐색 알고리즘 이용하지 X
- Feature map을 추출하는 CNN의 마지막 layer에 후보영역을 생성하는 별도의 CNN인 영역 제안 네트워크(RPN)* 적용
∴ CNN에서 추출된 Feature map을 RPN에서 추정된 후보 영역으로 잘라내어 객체 인식
- Feature map을 추출하는 CNN 과정과 후보영역을 생성하는 과정을 일련의 네트워크로 구성 -> 훈련시간 단축
*영역 제안 네트워크(RPN) : CNN 출력인 Feature map을 입력으로 받아 객체의 위치를 추정하여 후보영역을 출력하는 네트워크
R-FCN
- 위치 정보를 포함하고 있는 score map을 이용하여 물체의 위치 파악
- score map은 CNN을 통해 추출된 Feature map으로 부터 얻어짐, 각 score map은 영상 내 특정 위치의 정보를 포함
- score map을 이용하여 특정 위치마다 분류 결과를 얻어냄 -> 결과를 종합하여 최종적으로 특정 위치 내의 객체를 분류
- 특정 위치가 찾고자 하는 객체를 포함할 경우 score map의 반응 증가, 그렇지 않으면 반응 감소
- score map은 위치 정보를 포함하고 있으면서 훈련이 요구되지 않는다는 장점
- Faster R-CNN보다 훈련시간 3배정도 빠름
YOLO
- 객체 인식 문제를 하나의 회귀 문제로 접근하여 전체적인 구조를 간소화 -> 훈련 및 검출 속도 크게 향상
- 입력된 영상은 CNN을 거쳐 Tensor 형태로 출력 (이 Tensor는 영상을 격자 형태로 나누어 각 구현을 표현하며 이를 통해 해당 구역의 객체를 인식)
- 관심 영역을 추출하기 위한 별도의 네트워크가 필요하지 않음
- Faster R-CNN에 비해 빠른 훈련 속도, 정확도는 다소 떨어짐, 작은 물체 인식 어려움
SSD
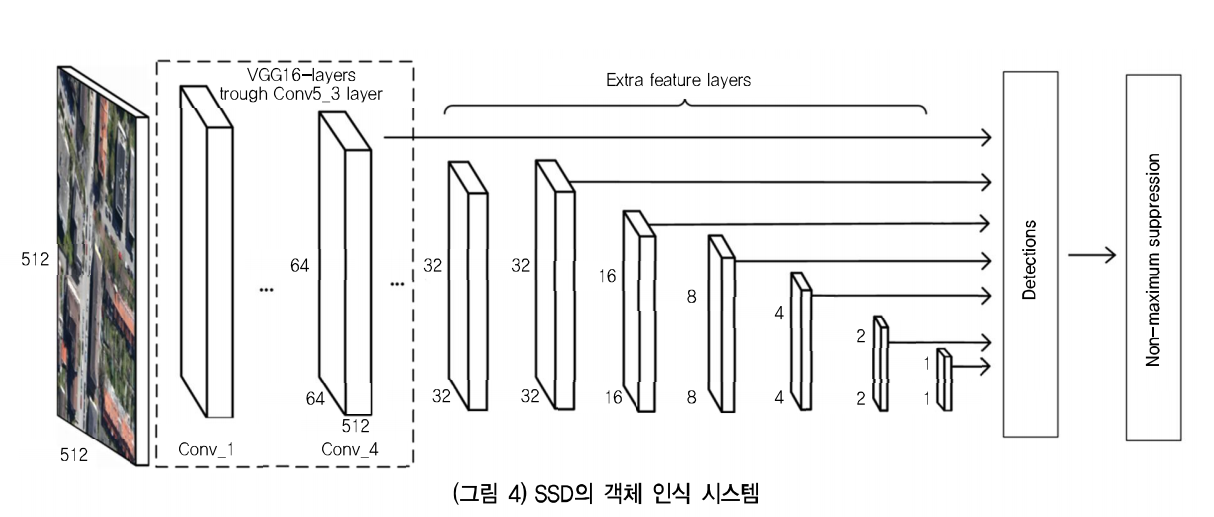
- RPN을 따로 훈련시키지 않고 다양한 크기의 Feature map을 이용하여 객체 인식
- CNN으로 얻은 Feature map은 Convolution layer가 진행됨에 따라 크기가 작아짐
- 위 과정에서 추출된 모든 Feature map들을 사용하여 객체 인식
-> 얕은 깊이에서의 크기가 큰 Feature map : 작은 물체 검출
-> 깊은 깊이에서의 크기가 작은 Feature map : 큰 물체 검출
- RPN을 제거함으로써 Faster R-CNN보다 훈련 속도 향상, 다양한 크기의 Feature map으로 YOLO보다 정확한 인식
실험 결과

R-FCN, SSD : 훈련시간은 적지만 정확도도 낮음
Faster R-CNN : 훈련시간은 오래걸리지만 정확도는 높음
반응형
'Implement > __Theory' 카테고리의 다른 글
| [CS231n] Lecture 2: Image Classification pipeline (0) | 2022.04.23 |
|---|





댓글 영역