고정 헤더 영역

상세 컨텐츠
본문
이번 기계학습 텀프로젝트로
분류, 회귀, 군집화 세 가지를 진행하였다.
그 중에서도 분류!!
- 데이터 선정

데이터셋 링크: https://www.kaggle.com/deepu1109/star-dataset (‘6 class csv.csv’ 파일)

Dataset은 kaggle의 “Star dataset to predict star types”로 선정하였다. 수업 자료에는 이진 분류를 하는 예제가 많아 이번 텀프로젝트에서는 다중분류를 진행하였다. 다양한 다중분류 중에서도 별을 좋아하여 별의 특성이 담긴 dataset을 이용하여 항성 분류를 하고자 하였다. 특히 이 dataset은 절대온도, 상대 반지름 등 다양한 수치 값을 기준으로 Star type이 결정되기 때문에 그 수치 값을 토대로 분류하기에 적절하다고 생각하였다.
Kaggle의 “Star dataset to predict star types” dataset은 절대 온도(Absolute Temperature), 상대 광도(Relative Luminosity), 상대 반지름(Relative Radius), 절대 크기(Absolute Magnitude), 별의 색상(Star Color), 스펙트럼 등급(Spectral Class), 그리고 Star Type이 있다. Star type은 나머지 피처들의 특성으로 결정된 것이다. Star type은 Red Dwarf, Brown Dwarf, White Dwarf, Main Sequence, SuperGiants, HyperGiants 6개의 class로 구성되어 있다. 6개의 Star type은 0~5의 숫자로 labeling 되어있다.
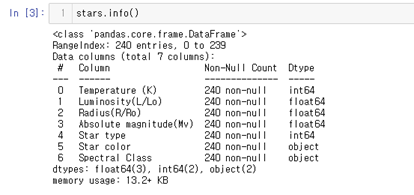
위 dataset에는 240개의 별의 data가 담겨있다.
- 데이터 전처리
data visualize에 유용하도록 dictionary를 만들어 dataset에 추가한다.



다음으로 missing data가 있는지 체크한다.

위와 같이 누락된 data는 없는 것으로 확인되었다.
이제 기록 방법만 다르고 같은 의미를 가진 항목을 같은 항목으로 교체해주어야 한다.
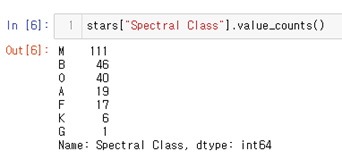
우선 Spectral Class의 경우를 살펴보면 7개의 스펙트럼 calss로 되어있어 바로 인코딩할 수 있다.
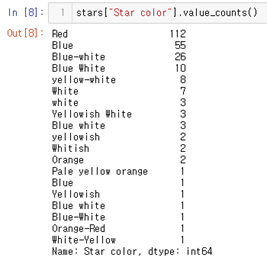
반면 Star color는 Blue-White, Blue White, Blue-white처럼 같은 색인데 다르게 쓰여진 색상들이 있어서 이를 수정해야한다.

모두 소문자로 바꾼 뒤, 띄어쓰기나 ‘-‘와 같이 color에 영향을 주지 않는 것은 지운다. 위처럼 같은 색인데 이름이 달랐던 데이터들이 사라진 것을 확인할 수 있다.

그리고 학습을 위해 Spectral Class와 Star color는 Label Encoding 과정을 통해 문자로 되어있는 data를 라벨 숫자로 변환한다.
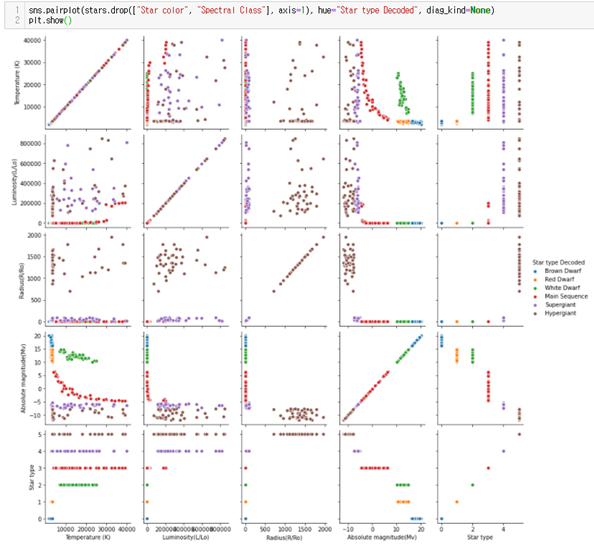
Pairplot을 통해 그래프를 출력하여 데이터를 시각화 해보았다. 이를 통해 data 컬럼들의 모든 조합에 대해 상관관계를 확인할 수 있다.
- 분류 및 파라미터 최적화

우선 정보를 통해 Star type을 알아내는 것이 목표이고 Star type의 정보들을 같이 학습시킨다면 정답을 다 알려주는 것이므로 Star type의 정보는 drop 시킨다.
그리고 모델을 생성하기 전에 데이터를 학습 데이터와 test 데이터로 나눈다. 학습데이터를 전체 데이터의 80%, test 데이터를 20%로 설정하였다. 그리고 학습 데이터에서 한 번 더 20%를 검증 데이터로 나누었다.
이후 데이터의 값이 너무 크거나 작은 경우에 모델 학습 과정에서 0으로 수렴하거나 무한으로 발산할 수 있기 때문에 StandardScaler를 통해 데이터를 scaling한다. StandardScaler는 각 feature의 평균을 0, 분산을 1로 변경한다.
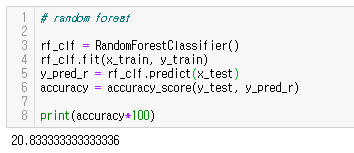
학습은 랜덤 포레스트를 사용하여 진행하였다. 랜덤포레스트는 배깅의 대표적인 알고리즘으로 여러 개의 결정 트리 분류기가 배깅 방식으로, 각자의 데이터를 샘플링하여 개별적으로 학습한 후 보팅을 통해 예측을 결정한다. 랜덤포레스트를 선정한 이유는 선정한 dataset의 크기가 크지 않아 overfitting의 우려가 있어 이를 방지하고자 선정하였다. 랜덤 포레스트에서 검증 데이터는 사용하지 않았다. 결과는 약 21%로 낮은 정확도를 보였다. 이유를 예상해보면 랜덤 포레스트가 변수의 수가 많을 때 성능이 떨어지는 문제가 있다고 하였는데 6개의 기준으로 Star type을 결정하기 때문에 변수의 수가 많아서 그런 것이 아닐까 생각해보았다. 그리고 max_depth를 설정해주지 않았기 때문에 깊이가 너무 깊어져서 overfitting이 일어난 것 같다. 그래서 파라미터 튜닝를 통해 성능을 높이고자 하였다.

Overfitting을 막기 위해 Max_depth와 min_child_weight, min_samples_split를 제한하였다. 그리고 GridSearchCV를 사용하여 최적의 파라미터를 찾아준다. Max_depth는 3, min_samples_leaf는 8, min_samples_split은 8, n_estimators는 100이 가장 성능이 좋았던 파라미터임을 알 수 있다. 파라미터를 튜닝하여 학습하였더니 시간은 조금 오래 걸렸지만 98%의 정확도로 성능이 많이 상승하였다. 이 결과를 통해 파라미터 튜닝 전의 낮은 정확도는 overfitting 때문이었을 것이라고 예상된다.


Overfitting이 적은 또 다른 방법인 XGBoost로도 분류를 해보았다. XGBoost는 Extreme Gradient Boosting의 약자로, Boosting 기법을 이용하여 구현한 알고리즘은 Gradient Boost 가 대표적인데 이 알고리즘을 병렬 학습이 지원되도록 구현한 라이브러리가 XGBoost이다. 여러 개의 Decision Tree를 조합해서 사용하는 Ensemble 알고리즘이다. 결과를 보면 약 96%의 정확도를 보이고, 최대 100%까지 정확도가 오르는 것을 확인하였다.
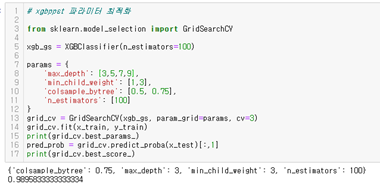
XGBoost 또한 파라미터 튜닝을 해보았다. Overfitting을 방지하기 위해 최대 깊이인 max_depth와 관측치에 대한 가중치 합의 최소인 min_child_weight 및 트리 생성에 필요한 피처의 샘플링에 사용되는 colsample_bytree를 제한하였다. colsample_bytree는 0.75, Max_depth는 3, min_chile_weight는 3, n_estimators는 100이 가장 성능이 좋았던 파라미터임을 알 수 있다. 그 결과 약 99%의 정확도로 좋은 성능을 보여주었다. XGBoost에 경우에는 파라미터를 튜닝하기 전과 후의 차이가 크지 않았다.
- 결과 및 분석, 고찰
파라미터 튜닝 한 랜덤포레스트와 XGBoost 모두 분류에 있어 좋은 결과를 보이는 것을 확인하였다. 최종적으로 랜덤포레스트보다 XGBoost가 성능이 더 좋았다. 그리고 파라미터 튜닝을 한 것이 안 한 것보다 성능이 좋게 나왔다. XGBoost의 경우 차이가 크진 않았지만 튜닝 전과 후 모두 좋은 성능을 보였기 때문에 파라미터 튜닝을 적절하게 해주는 것이 도움이 될 것이라고 생각한다. 이는 파라미터 튜닝을 통해 overfitting을 방지해주었기 때문이라고 추측하였다. 데이터가 많지 않아 overfitting이 발생할 수 있는 dataset이었기 때문에 파라미터 튜닝 전의 랜덤포레스트를 사용하여 분류하였을 때에는 overfitting 때문에 낮은 성능을 보였던 것 같다.
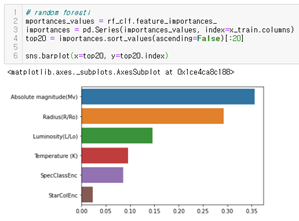

왼쪽은 랜덤포레스트의 피처 중요도, 오른쪽은 XGBoost의 피처 중요도이다. 랜덤포레스트에서는 절대 크기와 상대 반지름 피처가 분류에 큰 영향을 끼친 것으로 보인다. XGBoost는 상대 반지름이 압도적으로 영향을 많이 끼친 것을 확인할 수 있다. XGBoost에서 상대 반지름의 영향을 많이 받았으므로 이 피처를 제거하고 다시 학습을 진행해보았다.
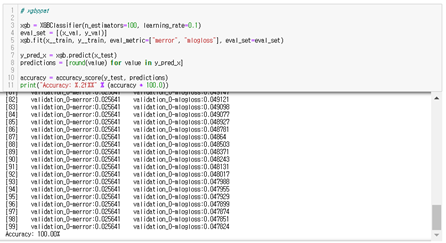

정확도는 모두 100%로 완벽한 성능을 보였다.

피처 중요도의 경우 상대 반지름을 제거하여서 그 다음으로 높았던 Luminosity가가장 높은 중요도를 보일 것이라고 예상했지만 절대 크기가 가장 큰 영향을 끼치고 있었다. 위 그래프는 랜덤 포레스트에서 Radius를 제외한 피처 중요도의 그래프 양상과 비슷한 결과임을 확인할 수 있었다. 결과를 통해 이 데이터셋을 사용하여 분류를 시도하였을 때 주로 절대 크기, 반지름에 의존하여 판단을 내리고 있음을 알 수 있다.
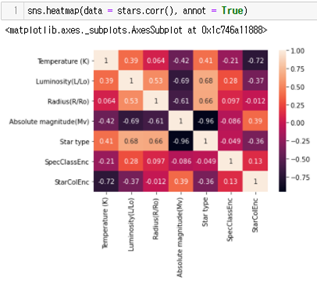
이 결과는 위 그래프를 통해서도 예측할 수 있다. 그래프는 heatmap을 통해 각 변수 간에 상관관계를 표로 나타낸 것이다. Star type과 상관 관계가 높은 세 가지 피처가 위 피처 중요도에서 가장 중요도가 높았던 상대 광도(Relative Luminosity), 상대 반지름(Relative Radius), 절대 크기(Absolute Magnitude)인 것을 확인할 수 있다.
캐글에 있는 데이터 셋이고
다른 사람들의 자료를 조금 참고하긴 했지만
전처리 이후 과정은 강의자료를 참고하여 혼자서 진행했다!
틀린 부분이 있을 수 있으니
이상한 부분 댓글남겨주시면 감사하겠습니당 ㅎㅁㅎ
분류 끝!
반응형
'Implement > __Process' 카테고리의 다른 글
| [ML] Python AutoML 사용해서 모델 비교하기 - pycaret 라이브러리 (0) | 2023.06.11 |
|---|---|
| [YOLO-darknet] Window 10에서 YOLO 사용하기 (1) | 2020.08.29 |





댓글 영역