고정 헤더 영역

상세 컨텐츠
본문
머신러닝으로 문제를 해결하고자 하는데
어떤 알고리즘을 써야할지 모르겠다면?
Auto ML을 사용해보기!
회사에서 프로젝트를 진행하면서
머신러닝 기법으로 Binary Classification을 진행해야했는데
어떤 알고리즘을 써야할지 막막했다..
하나하나 구현해서 다 써볼 수도 없고!!
이럴 땐 ~?
Auto ML을 사용하면 편하다!!
우선
Auto ML 이란?
시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스
이며 일일이 알고리즘 선택 및 튜닝을 진행해줘야 하는 작업들을
자동으로 해주는 것이다!
분류, 회귀, 시계열 예측 등 여러 문제 해결에 사용할 수 있다고 함
이런 이론적인 내용은 다른 분들이 자세히 적어두었을테니
찾아보시고..
오늘은
python으로 pycaret이라는 라이브러리를 이용해서
binary classification을 구현할 것이다!
Pycaret은 python에서 제공하는 AutoML라이브러리이다.
1. 공식 문서 설명이 친절하게 나와있고
2. 구현이 쉽다
는 장점이 있다!
(공식 문서 : https://pycaret.gitbook.io/docs/)
이제 본격적으로 시작해보자!!
우선 라이브러리를 사용하기 위해 설치부터 해주자!
1. Pycaret 라이브러리 설치
pip install pycaret위처럼 간단하게 pip 을 사용해서 설치하면 된다.
설치가 완료 되었다면
2. pycaret 라이브러리 import

from pycaret.classification import *위처럼 라이브러리 import 해주고
(나는 classification 할거라서 이 부분만 import 했다)
3. dataset split
데이터셋 같은 경우에는
자신이 사용할 데이터로 하면 되고
나는 train_test_split 함수 사용해서 나누는 과정부터 진행할 예정이다!
데이터셋 알아서 준비해오도록!
x_train, x_valid, y_train, y_valid = train_test_split(all_features_data, y_f, test_size=0.33, stratify=y_f)이런 식으로 함수 사용해서 나누면 되는데
from sklearn.model_selection import train_test_split이 친구도 사용하려면 라이브러리 Import 해줘야하는거 잊지 말고~
4. Setup
그리고 나서 이제
환경을 Initialize하는 과정이라고 보면 된다.
clf = setup(data=x_train, target=y_train, remove_outliers=True)data : train data (x)
target : train data의 target (y)
remove_outliers : True로 하면 학습 전에 데이터에서 outlier들을 알아서 지워준다
5. 모델 비교
top5_models = compare_models(fold = 5, round = 3, sort = 'AUC', n_select = 5)여러 모델들을 적용해서 성능들을 비교한다.
fold : cross validation의 Fold
round : 반올림 할 소수자릿수
sort : 정렬 기준
n_select : 반환 할 Top_n 모델 수, 상위 몇 개 까지 볼건지
이고
이를 실행해서
print(top5_models)로 출력을 해보면
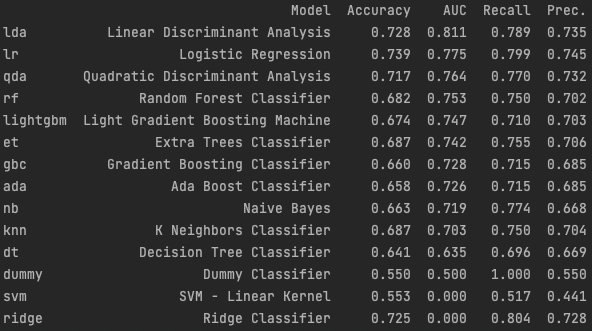
이런 식으로 출력이 된다.
(n_select를 5로 했는데 14개가 다 출력되는걸 보면
print로는 다 출력이 되고 모델 반환만 5개가 되는 것으로 추정됨)
위 결과를 통해 내가 사용한 데이터로는
Linear Discriminant Analysis를 사용했을 때 가장 성능이 좋은 것을 확인할 수 있다.
이런 식으로 어떤 알고리즘을 사용할지 모르겠을 때
Auto ML을 통해 가이드라인을 잡으면 빠른 문제 해결에 도움이 된다.
전체 코드
from pycaret.classification import *
from sklearn.model_selection import train_test_split
### 데이터셋 알아서 불러오기!!
x_train, x_valid, y_train, y_valid = train_test_split(all_features_data, y_f, test_size=0.33, stratify=y_f)
## all_features_data : x 데이터
## y_f : y 데이터
y_train = np.array(y_train, dtype=np.int32)
clf = setup(data=x_train, target=y_train, remove_outliers=True)
top5_models = compare_models(fold = 5, round = 3, sort = 'AUC', n_select = 5)
print(top5_models)+ 추가 정보
이렇게 나온 결과를 이용해서
pycaret 라이브러리에 있는
create_model(), tune_model() 함수를 이용해서
모델 구현 및 하이퍼파라미터 자동 튜닝 또한 진행할 수 있다.
blend_models()함수를 사용하면
여러 모델을 혼합해서 사용할 수도 있다고 하는데
이거는 아직 시도해보지 않았다!
어떤 알고리즘을 사용할지 비교하는 것 뿐만 아니라
모델 구현까지 Pycaret으로 진행할 예정이라면
위 추가적인 함수들도 사용해보면 좋을 듯~
pycaret 라이브러릴르 사용해서 Auto ML로
모델 성능 비교하는 과정을 진행해보았다.
알고리즘 선정에 머리를 쥐어짜고 있는 누군가에게
도움이 되었으면 좋겠다!
그럼 안뇽~
오랜만에 글 쓰려니 힘들다..
__END__
반응형
'Implement > __Process' 카테고리의 다른 글
| [Machine Learning] 분류 (Star dataset to predict star types dataset) (1) | 2021.01.01 |
|---|---|
| [YOLO-darknet] Window 10에서 YOLO 사용하기 (1) | 2020.08.29 |





댓글 영역